Angr 学习笔记
本文最后更新于:2024年7月12日 上午
Angr学习笔记
前言
本文记录一下Angr的基本使用方法,主要是基于Github上的开源项目以及笔记AngrCTF_FITM整理,Angr在逆向方面确实用处比较大,特此记录一下。
什么是Angr
angr是一个用于分析二进制文件的python框架。它专注于静态和符号分析,使其适用于各种任务。项目地址:https://github.com/angr
符号执行
符号执行就是在运行程序时,用符号来替代真实值。符号执行相较于真实值执行的优点在于,当使用真实值执行程序时,我们能够遍历的程序路径只有一条, 而使用符号进行执行时,由于符号是可变的,我们就可以利用这一特性,尽可能的将程序的每一条路径遍历,这样的话,必定存在至少一条能够输出正确结果的分支, 每一条分支的结果都可以表示为一个离散关系式,使用约束求解引擎即可分析出正确结果。
个人理解为Angr就是将输入作为一种可变符号,各种条件分支作为路径分支,符号执行实际上就是在走迷宫,最终得到到达终点的正确路径。
0x00 一般模板
题目:00_angr_find
直接拖到ida中查看源码:
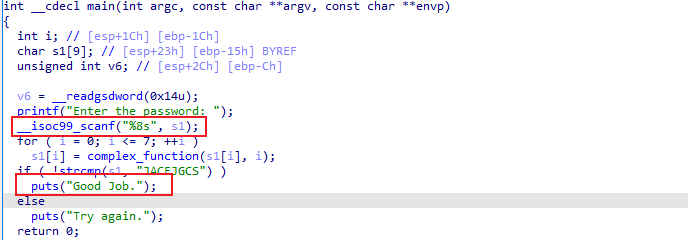
主要逻辑就是对于输入的字符串进行complex_function变换然后比较。
1 | |
project = angr.Project(bin_path, auto_load_libs=False)Angr使用
Project作为二进制文件的基本映像,auto_load_libs=False避免程序导入不必要的库,否则分析到库函数调用时也会进入库函数,这样会增加分析的工作量,也有可能会跑挂。initial_state = project.factory.entry_state()Angr并不是真正的运行程序,而是模拟程序的运行路径,因此Angr提供
state来记录程序模拟时的状态(记录一系列程序运行时的信息,如内存/寄存器/文件等,类似于快照),project.factory.entry_state用于提供程序初始化状态。simulation = project.factory.simgr(initial_state)基于状态创建程序模拟管理器
simulation,用于控制程序的模拟执行,从我们提供的初始化状态initial_state开始。simulation.explore(find=is_successful, avoid=should_abort)符号执行最普遍的操作时找到能够到达某个地址的状态,
simulation提供了``explore()方法寻找路径,启动后程序会一直执行,直到发现了一个和find参数指定的条件相匹配的状态。其中find和avoid参数可以为;- 具体地址
- 具体地址的列表集合
- 以
state为参数的判断函数(本题解中就是用的这种方式)
sys.*.fileno()sys.stdin.fileno()标准输入文件描述符,值为0;sys.stdout.fileno()标准输出文件描述符,值为1;sys.stderr.fileno()标准错误文件描述符,值为2。
state.posix.dumpsstate.posix.dumps(0)代表该状态程序的所有输入,state.posix.dumps(1)代表该状态程序的所有输出。
0x01 输入的参数存放在寄存器中
日常IDA查看一下主函数:
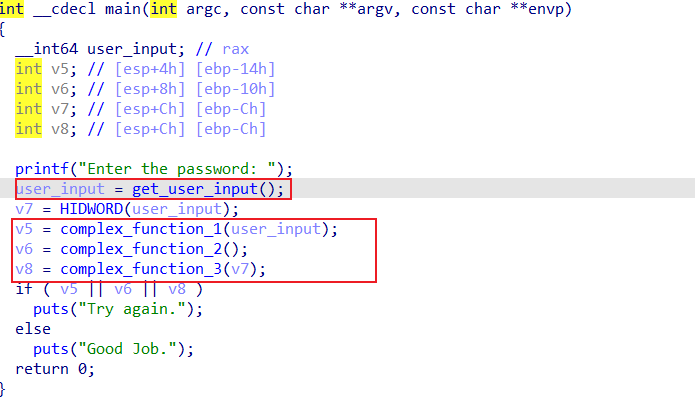
程序通过get_user_input读取输入,并存放至eax、ebx、edx,当然我们可以使用上一题那样直接进行路径搜索,但是angr在处理复杂格式的字符串输入时优化不是很好,最好的办法是绕过scanf函数,直接将符号注入到寄存器中。
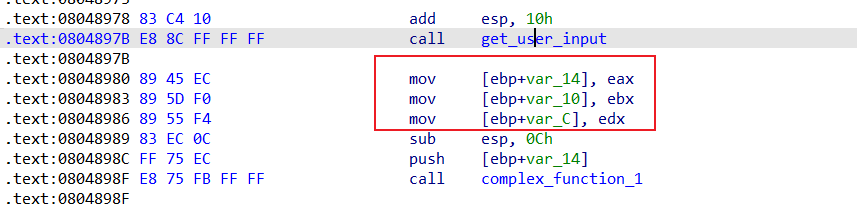
complex_function_1、complex_function_2、complex_function_3密码加密函数,也是我们用于路径寻找的点。
1 | |
为了绕过
get_user_input输入函数,我们不能从main函数的开头开始,通过使用start_address定位到get_user_input下一条指令,即0x08048980,在此处构造程序状态。project.factory.blank_state当我们不使用main函数作为程序入口时,初始化状态就不能够使用
entry_state(),好在project.factory提供了其他的函数初始化状态:名称 描述 entry_state()构造一个从函数入口点执行的已初始化状态 blank_state()在指定的入口地址处构造一个“空状态”,该的数据都是未初始化的,当使用未初始化的的数据时,一个不受约束的符号值将会被返回。 call_state()构造一个已经准备好执行某个函数的状态 full_init_state()构造一个已经执行过所有与需要执行的初始化函数,并准备从函数入口点执行的状态。比如,共享库构造函数(constructor)或预初始化器。当这些执行完之后,程序将会跳到入口点。 passwd0 = claripy.BVS('passwd0',passwd_size_in_bits)构造了一个名为
passwd0的符号位变量,符号位向量是angr用于将符号值注入程序的数据类型。这些将是angr将解决的方程式的“x”,也就是约束求解时的自变量。可以通过BVV(value,size)和BVS( name, size)接口创建位向量,也可以用FPV和FPS来创建浮点值和符号。initial_state.regs.eax = passwd0将符号变量
passwd0注入eax寄存器中。solution_state.solver.eval(passwd0)返回的是
passwd0的一个十进制解,用format将其16进制化。这里:solver.eval(expression):将会解出expression一个可行解。solver.eval_one(expression):将会给出expression的可行解,若有多个可行解,则抛出异常。solver.eval_upto(expression, n):将会给出最多n个可行解,如果不足n个就给出所有的可行解。solver.eval_exact(expression, n):将会给出n个可行解,如果解的个数不等于n个,将会抛出异常。solver.min(expression):将会给出最小可行解。solver.max(expression):将会给出最大可行解。
solution_state.solver.eval与state.posix.dumps的区别:
state.posix.dumps一般在未定义BVS时打印我们想要的结果,而solution_state.solver.eval一般用于定义了BVS,打印BVS的结果。
0x02 输入参数存放在栈上
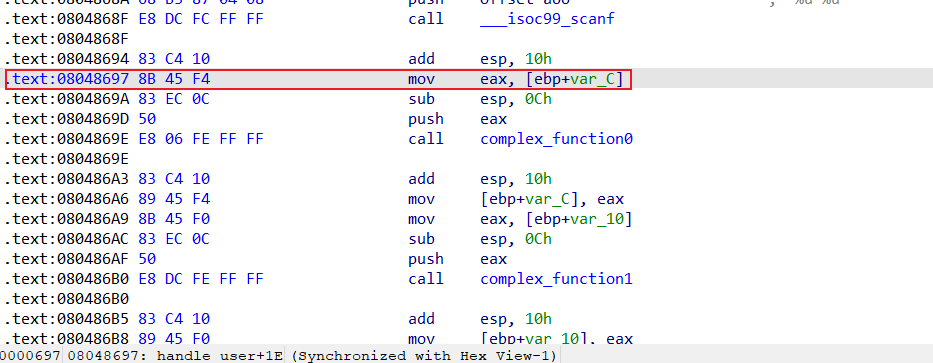
直接拖进IDA进行分析,可以看的handle_user为主逻辑,并且scanf读取的数据是直接写在栈上的,那么我们注入寄存器的方法就是失效了,现在尝试直接注入栈空间。
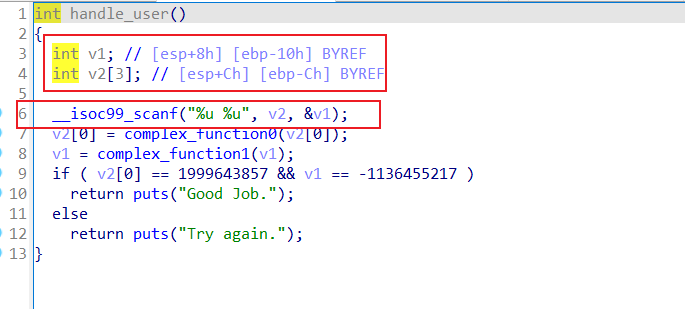
同样设置初始化状态为scanf之后,即0x08048697,这里有小伙伴可能会有疑问了,scanf后面明明是0x08048694为什么是要使用下一条指令呢,原因是add esp,10h是在清理scanf的栈帧,可能会对我们的esp造成影响,因此我们这里直接跳过了scanf栈帧的清理,否则还需要对esp进行相应的处理。
1 | |
initial_state.regs.ebp = initial_state.regs.esp由于我们使用的是
project.factory.blank_state初始化的状态,该状态内的数据都是未初始化的,并且后面执行的代码使用到了栈上的数据,因此我们需要手动构建当前状态的栈帧。initial_state.regs.esp -= padding_length_in_bytes通过汇编代码我们可以得知:求解的
passwd0和passwd1分别位于栈上ebp-0xc和ebp-0x10位置,也就是说栈上有8个字节是被占用的,我们需要手动填充这些字节,然后将符号入变量入栈,保证汇编代码的正确性。另一种不用压栈的方法就是直接将esp移动至相应位置,直接向该地址写入符号位变量,但是下面的解法是有问题,最终输出的结果不对,我也不清楚那里的问题,望大佬告知。1
2
3
4
5
6initial_state.regs.rbp = initial_state.regs.rsp
passwd0_addr = initial_state.regs.esp - 0xc
passwd1_addr = initial_state.regs.esp - 0x10
initial_state.regs.esp -= 0x10
initial_state.memory.store(passwd0_addr, passwd0)
initial_state.memory.store(passwd1_addr, passwd1)
0x03 传入的参数存在全局变量区
主函数:
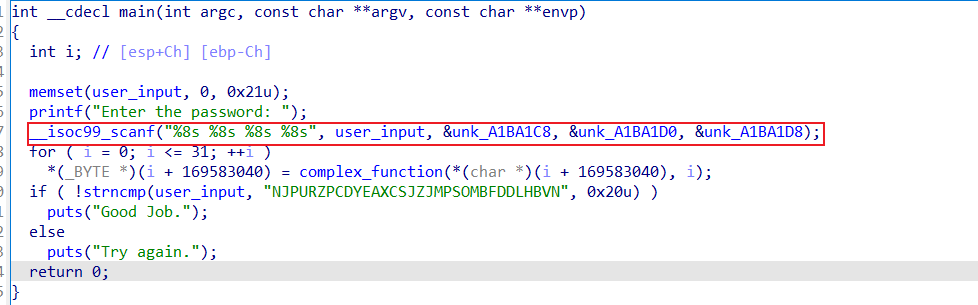
这道题目解法与之前的类似,主要区别在于scanf输入的内容存储在.bss段,而.bss段默认是程序启动时,由系统自动分配的空间,因此如果我们想要跳过scanf时,就必须要将符号位变量写入至.bss段的相应位置。
1 | |
initial_state.memory.store这里用到的访问方式是
state.memory.store和state.memory.load,可以用来访问一段连续的内存。由于4个变量是连续存储,直接按8字节叠加即可。load(addr,...): 读取指定地址的内存
1
2
3
4
5
6
7
8
9
10
11def load(self, addr, size=None, condition=None, fallback=None, add_constraints=None, action=None, endness=None, inspect=True, disable_actions=False, ret_on_segv=False):
"""
Loads size bytes from dst.
:param addr: The address to load from.
:param size: The size (in bytes) of the load.
:param condition: A claripy expression representing a condition for a conditional load.
:param fallback: A fallback value if the condition ends up being False.
:param add_constraints: Add constraints resulting from the merge (default: True).
:param action: A SimActionData to fill out with the constraints.
:param endness: The endness to load with.
"""store(addr, ...): 向指定内存写入数据
1
2
3
4
5
6
7
8def store(self, addr, data, size=None, condition=None, add_constraints=None, endness=None, action=None,
inspect=True, priv=None, disable_actions=False):
"""
Stores content into memory.
:param addr: A claripy expression representing the address to store at.
:param data: The data to store (claripy expression or something convertable to a claripy expression).
:param size: A claripy expression representing the size of the data to store. #大小
...
0x04 传入的参数存放在堆上
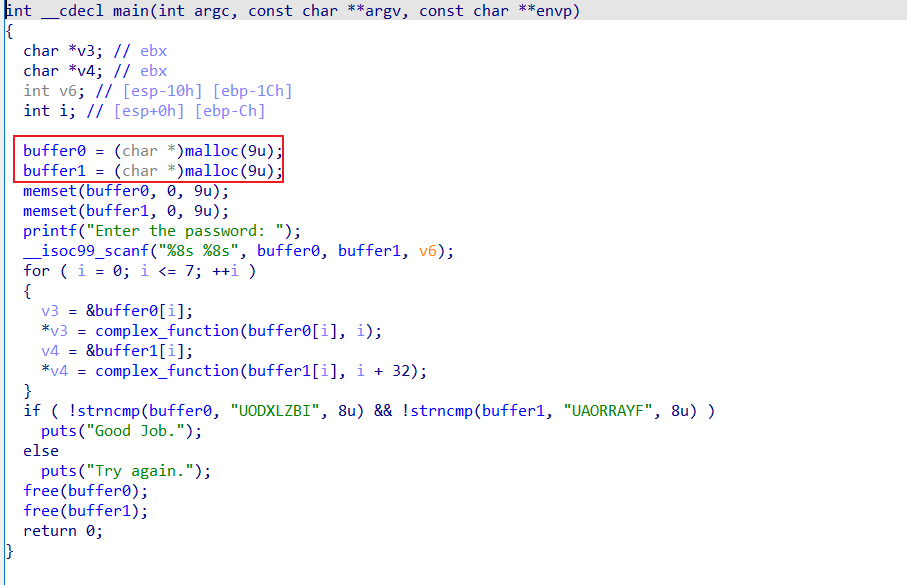
题目:06_angr_symbolic_dynamic_memory
1 | |
initial_state.memory.store(fake_heap_address1, passwd1)由于我们跳过了程序初始阶段,
buffer0和buffer1并未进行malloc,因此我们需要手动模拟分配空间malloc的操作。initial_state.memory.store能够在内存中写入数据,因此完全可以用来模拟malloc,直接将符号位向量写入内存空间。buffer0和buffer1存储的是申请到的堆内存地址,angr并没有真正“运行”二进制文件,它只是在模拟运行状态,因此它实际上不需要将内存分配到堆中,实际上可以伪造任何地址。而需要使用者做的就是选择两个地址存放的堆区地址,buffer0和buffer1就是可选项。0xffffc900和0xffffc955随机伪造的地址。initial_state.memory.store(pointer_to_malloc_memory_address0,fake_heap_address0, endness=project.arch.memory_endness)空间分配好之后,我们直接将空间地址写入
buffer0和buffer1,这两个变量又是在.bss,因此需要进行内存写入。.store参数endness用于设置端序,angr默认为大端序,总共可选的值如下:LE– 小端序BE– 大端序ME– 中间序
总结
今天简单练习了angr_ctf的前六道题,感觉angr比我想象中的要强大,但是使用angr过程中也应该注意:angr实际上是一种路径探索的方法,在处理分支时,采取统统收集的策略,因此每当遇见一个分支,angr的路径数量就会乘2,这是一种指数增长,也就是所说的路径爆炸。执行上很像BFS,一旦分支过多,angr就无法较为快速的求解了,因此在使用过程中应该尽可能对源程序进行处理,最好能够减少分支路径。